Time Series Data Part 3: Custom Model Tuning🔗
tl;dr:
How to Train Your Model🔗
In Machine Learning our goal is to predict things based on some input data and usually a whole lot of training data. The accuracy of the model's predictions are determined by a variety of factors:
- Architecture
- Training Data
- Hyperparameters
Each of these affects your training results and model outputs in different ways. Testing different Architectures, Datasets, and Hyperparameters is paramount to getting the best results possible.
People call each phase different things but you'll often hear terms such as:
- Model Selection
- Data Cleaning / Augmentation
- Hyperparameter Tuning / Grid Search
In this post we'll go over each of these with a primary focus on Hyperparameter Tuning.
Model Selection🔗
First up, there are many Machine Learning model "architectures" in the world.
Some are basically as simple as an if statement (perceptrons).
Some require more computing power than any normal user could afford.
The architecture will determine the math the model computes in making a prediction out of an input. The linear combinations from input to output are defined in this way by the model architecture.
Time Series Forecast models (those that predict future observations of a Time Series) have several restrictions for different types of training. The labels below are not mutually exclusive, but they do determine whether a given model can be trained on a given set of data.
- Univariate Capable Models
- Can train and predict on a Univariate (single value column) time series
- Ex. Temperature
- Multivariate
- Can train and predict on a Multivariate (multiple value columns) time series
- Ex. Temperature and Humidity
- Probabilistic
- Produces an output based on some random element. Non-deterministic predictions.
- All neural network based methods have Probabilistic output
- Multiple-series training
- Can train and predict on multiple (potentially unaligned) time series'
- Ex. Train on many different stock IPOs
- Past-observed covariates support
- Can train and predict utilizing an additional time series that provides known past data
- Ex. Humidity when you're only trying to predict Temperature
- Future-known covariates support
- Can train and predict utilizing an additional time series that provides known future data
- Ex. Day of the Week, Month of the Year, other forecasts
Tabular Models in Time Series🔗
Research and industry have found time and again that tabular regression based models such as LightGBM, Random Forests, and XGBoost perform just as well if not better than models specifically architected for Time Series data.
Dataset Selection and Cleaning🔗
When diving into a Machine Learning project the training dataset needs to mimic the real world data that will be used as input. Because of this, you'll likely choose your starting dataset before settling on a model.
That's ok though, because there is more to a Dataset than meets the eye.
Some common tasks that go along with handling Time Series datasets:
- Removing known outliers and other bad data points
- Merging Multiple Time Series into a Multivariate Time Series
- Adding Future or Past Covariates
- Splitting into Train, Validation, Test Data
- In Time Series this is often split at a certain date into Train and Validation
Hyperparameter Tuning🔗
Model / Training Hyperparameters are specific to each model and are decided before the training happens. In Time Series models they include things such as:
- Seasonality Period
- Additive vs Mutliplicative Seasonality
- Number of differentiations
- Size of moving windows (avg, max, min, etc.)
Each unique combination of Hyperparameters that a particular model can have will yield different results.
For this reason it's important to try different values for each. It also implies we can use certain default values as a "baseline" for each model.
Comparing results from different every possible combination of Hyperparameters to the baseline results lets you pick the best performance that model could have had on the dataset. This implies improving performance means changing to a different model architecture or changing the dataset, which were the topics above!
Usually choosing all of the combinations is not feasible. It takes a lot of computing power in some circumstances!
Nevertheless, the process of picking a range of values to try for different Hyperparameters is commonly called "Grid Searching." The range of values depends on the model, how much time / computing power you have, and what you know about the model behaviour on similar data.
For example, for data that appears to have a yearly seasonal trend, it would be a waste of resources to include period values very far from one year in the grid search. The results of a model trained with those Hyperparameters far away from the real trend are very likely to yield bad results.
(note: using those model results as a baseline or to understand the model better is totally fine if you have the time and computing resources!)
Model, Data, and Hyperparameter selection with Darts and Streamlit🔗
A playground web app for the Darts API with Streamlit!
Featuring:
- Example datasets
- Upload your own dataset
- Model training tuning
- Model forecasting and plotting controls
- Downloadable forecasts
Explore A Time Series!🔗
Use your own csv data that has a well formed time series and plot some forecasts!
Or use one of the example Darts datasets
Explorable Models🔗
- NaiveDrift
- NaiveMean
- NaiveSeasonal
- ARIMA
- VARIMA (Requires Multivariate dataset)
- ExponentialSmoothing
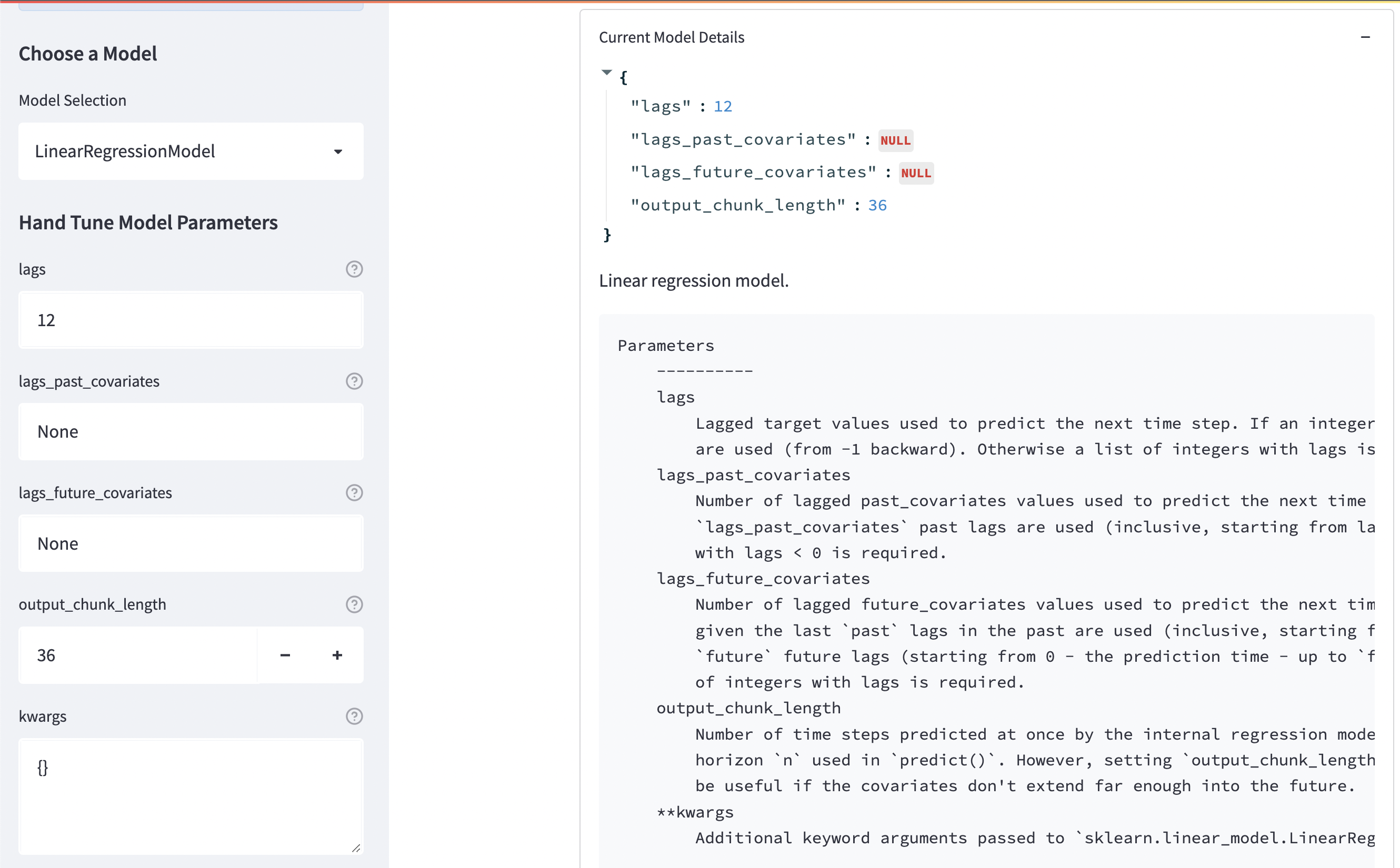
- LinearRegressionModel (Hand set Lag)
- FFT
- Theta
- FourTheta
- KalmanForecaster
- LightGBMModel
- RandomForest (Hand set Lag)
- RegressionModel
Created: June 7, 2023